一般来说,我们希望搜索蜘蛛光顾我们的网站越多越好,我相信每个新手站长都会是站长工具的常客,一大早起来就是关注自己网站的收录量.收录量的增长是一张晴雨表,升则忧、降则喜,我想告诉广大的站长朋友这完全没有必要,收录量不是目的,我觉得我们关注的重点应该是怎样让自己的网站拥有更多的百度搜索流量。
robots.txt是搜索引擎爬行网站的控制文件,按照一定的语法告诉搜索引擎哪些网页能爬,哪些不能爬,对于robots.txtd的介绍和书写语法,你可以参考这篇博文:网络蜘蛛访问控制文件robot.txt的写法 。
可能你想说,收录量不是越多越好吗?
其实不然,网站的网页不是收录越多越好,大家都知道搜索引擎比较网络上的网页相似度(相似度太高的两个页面会分散权重)的时候,不仅仅会进行不同网站间的纵向比较,而且会进行同一网站不同页面间的比较,所以,比如对于个人博客的作者归档和首页,页面内容差不多一样,我们完全可以屏蔽蜘蛛访问作者归档的页面。下面我来详细地介绍一下wordpress怎样写robots.txt利于SEO优化。
一、屏蔽没有必要收录的一些链接
1、屏蔽捉取站内搜索结果
Disallow: ?s=*
这个就不用解释了,屏蔽捉取站内搜索结果。站内没出现这些链接不代表站外没有,如果收录了会造成和TAG等页面的内容相近。
2、屏蔽Spider捉取程序文件
Disallow: /wp-*/
屏蔽spider捉取程序文件,wp-*表示wp-admin,wp-include等文件夹都不让搜索蜘蛛爬行,这节约了搜索引擎蜘蛛资源。
3、屏蔽Feed
Disallow: /feed/*
Disallow: /*/*/feed/*
Disallow: /*/*/*/feed/*
头部代码里的feed链接主要是提示浏览器用户可以订阅本站,而一般的站点都有RSS输出和网站地图,故屏蔽搜索引擎抓取这些链接,相当有必要,应为feed里面的内容基本就是你文章内容的重复,相同内容会让百度降低单页面权重,同时这也节约蜘蛛资源和服务器的压力。
4、屏蔽捉取留言信息链接
Disallow:/*?replytocom*
Disallow: /comments/
Disallow: /*/comments/
屏蔽留言信息链接。需要指出的是,屏蔽留言信息链接不是说不让蜘蛛收录你文章的评论页面,而是这样的链接打开后,整个页面就只有一个评论,完全没有被收录的必要,同时也节约蜘蛛资源,故屏蔽之。
5、屏蔽其他的一些链接,避免造成重复内容和隐私问题
Disallow: /date/
Disallow: /author/
Disallow: /category/
Disallow: /?p=*&preview=true
Disallow: /?page_id=*&preview=true
Disallow: /wp-login.php
这些屏蔽规则你可以根据自己的需求决定是否创建,屏蔽data、author、category等页面都是为了避免太多重复内容,
6、Disallow: /?P=*
屏蔽捉取短链接。默认头部里的短链接,百度等搜索引擎蜘蛛会试图捉取,虽然最终短链接会301重定向到固定链接,但这样依然造成蜘蛛资源的浪费。
7.屏蔽特定格式
Disallow: /*.js$
Disallow: /*.css$
屏蔽对js、css格式文件的抓取,节约蜘蛛资源,降低服务器压力,你可以根据实际要求是否屏蔽你的图片被抓取。
8.其它不想被抓取的页面
Disallow: /*?connect=*
Disallow: /kod/*
Disallow: /api/*
- /*?connect=*:我的博客登录链接
- /kod/*:在线文件管理链接
- /api/*:我自制的API链接
二、使用Robots.Txt需要注意的几点地方:
- 1、有独立User-agent的规则,会排除在通配“*”User agent的规则之外;
- 2、指令区分大小写,忽略未知指令,下图是本博客的robots.txt文件在Google管理员工具里的测试结果;
- 3、“#”号后的字符参数会被忽略;
- 4、可以写入sitemap文件的链接,方便搜索引擎蜘蛛爬行整站内容。
- 5、每一行代表一个指令,空白和隔行会被忽略;
- 6、尽量少用Allow指令,因为不同的搜索引擎对不同位置的Allow指令会有不同看待。
上面的这些Disallow指令都不是强制要求的,可以按需写入。也建议站点开通百度站长工具,检查站点的robots.txt是否规范。
三、百度站长工具Robots.Txt工具的使用方法
百度站长工具robots.txt工具网址:http://zhanzhang.baidu.com/robots/index
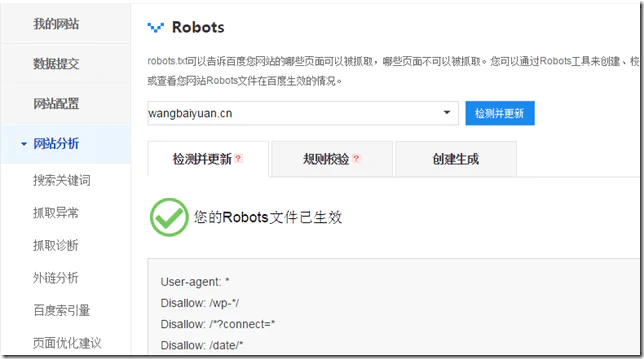
百度站长工具robots.txt工具的使用方法
- 检测并更新:在文本框里输入网站点击检测并更新,百度将抓取你的robots.txt文件,如果你近期robots.txt最近有更新,这将马上通知百度搜索蜘蛛更新它的爬行规则,使你修改后的robots.txt马上生效。
- 规则校验:你可以提取自己的robots.txt,然后验证一下你的robots.txt语法是否正确,检验你想要禁止蜘蛛爬行的网址是否能有效屏蔽;
- 创建生成:根据你的需求,傻瓜式地生成robots.txt,对于站长小白不妨一试。
附录
本站robots.txt分享如下:
本站 robots.txt分享
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | User–agent: * Disallow: /wp–*/ Disallow: /*?connect=* Disallow: /date/* Disallow: /kod/* Disallow: /api/* Disallow: /*/trackback Disallow: /*.js$ Disallow: /*.css$ Disallow:/*?replytocom* Disallow: /comments/ Disallow: /*/comments/ Disallow: /feed/* Disallow: /*/*/feed/* Disallow: /*/*/*/feed/* Disallow:/articles/* Disallow:/shuoshuo/* Sitemap: http://wangbaiyuan.cn/sitemap_index.xml |
{kind=link}