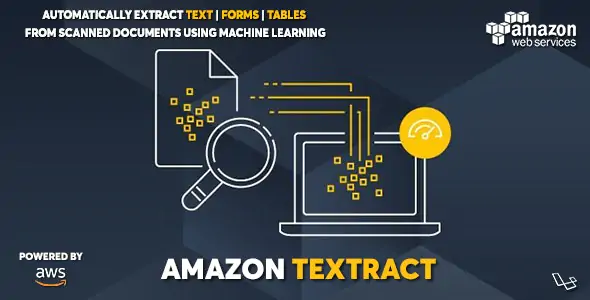
iExtractor是一款基于Amazon AWS机器学习服务的智能文字识别提取系统PHP源码,使用机器学习 (ML) 服务自动从扫描的文档中提取文本、笔迹和数据。它超越了简单的光学字符识别 (OCR) 来识别、理解和从表单和表格中提取数据。
今天,许多公司手动从扫描的文档中提取数据,例如PDF、图像 (PNG | JPEG)、表格和表单,或者通过需要手动配置的简单 OCR 软件(通常必须在表单更改时进行更新)。为了克服这些手动和昂贵的过程,iExtractor使用 ML 来读取和处理任何类型的文档,无需手动操作即可准确地提取文本、笔迹、表格和其他数据。iExtractor可以在几分钟而不是几小时或几天内提取数据。
此外,您可以利用收据分析功能在收据上找到供应商名称,即使它仅显示在页面上的Logo中,而没有明确的标签称为“供应商”。它还可以查找和提取未使用行项目列标题标记的项目、数量和价格。
作为AWS免费套餐的一部分,您可以免费开始使用Amazon Textract。免费套餐为期 3 个月,新的 AWS 客户每月最多可以使用文本任务分析 1,000 页,使用表单或表格任务每月最多可以分析 100 页。
说明:该源码是官方购买原封打包分享,未激活未去授权,需要激活版的价格加100
演示系统
查看演示
源码特点
- 由Amazon AWS提供支持
- 支持6 种语言的文档(EN | FR | DE | IT | PT | ES)
- 支持PDF|PNG|JPEG格式的文档
- 支持英文手写文件
- 自动识别键值对
- 自动识别表值
- 摘要和项目数据的收据分析
- 支持PNG 格式的文档 | JPEG格式最大10MB
- 支持最大500MB的PDF格式文档
- 支持多达3000页的PDF格式文档
- 无需机器学习专业知识
- 快速准确地提取数据
- 无需维护代码或模板
- 降低文件处理成本
- 图像扫描仪
- PDF 扫描仪
- 完全响应的界面
- 密切监控文本服务的估计支出
- 强大的管理面板
- 使用 PHP 7.4.x 和 Laravel 8.4.x 开发
- 详细而全面的文档
- =====================================================
- Powered By Amazon Web Services
- Support for documents in 6 Languages (EN | FR | DE | IT | PT | ES)
- Support for documents in PDF | PNG | JPEG formats
- Support for handwritten documents in English language
- Identify Key Value Pairs Automatically
- Identify Table Values Automatically
- Receipt Analysis for Summary and Item data
- Support for documents in PNG | JPEG formats up to 10MB in size
- Support for documents in PDF format up to 500MB in size
- Support for documents in PDF format up to 3000 pages
- No Machine Learning expertise required
- Extract data quickly & accurately
- No code or templates to maintain
- Lower document processing costs
- Image Scanner
- PDF Scanner
- Fully Responsive Interface
- Closely Monitor Estimated Spending for Textract Services
- Powerful Admin Panel
- Developed with PHP 7.4.x and Laravel 8.4.x
- Detailed and Comprehensive Documentation
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
{kind=link}