
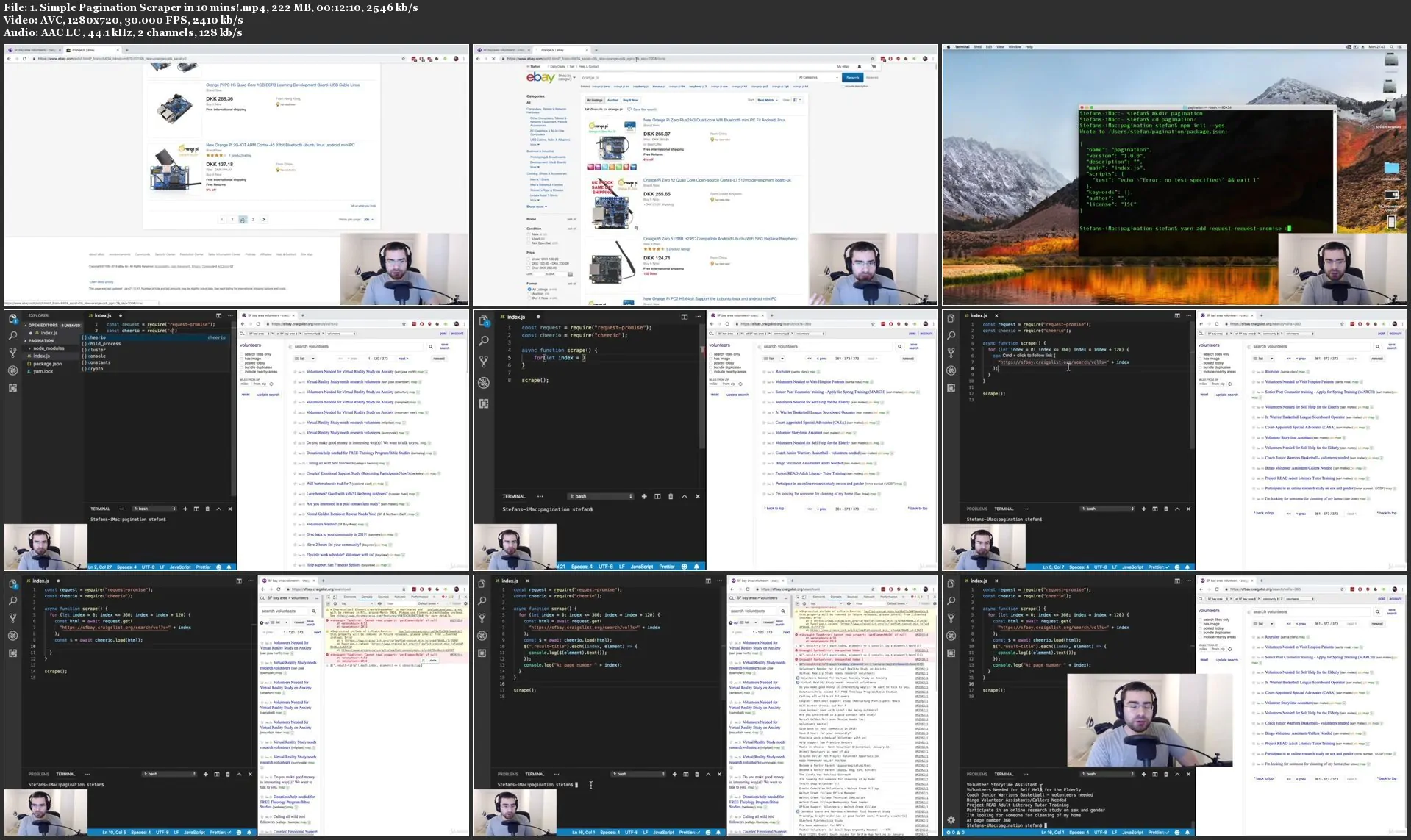
在本课程中,您将学习如何抓取网站,并在实际网站上使用JavaScript Nodejs Request,Cheerio,NightmareJs和Puppeteer进行实践示例。您将在async / await中使用最新的JavaScript ES7语法。
您将学习如何使用Node.js Request和Cheerio抓取Craigslist网站进行软件工程工作。您将在async / await中使用最新的JavaScript ES7语法。
然后,您将学习如何使用NighmareJs和Puppeteer抓取需要JavaScript的更高级的网站,例如iMDB和AirBnB。
我还要向您展示一个实用的真实网站,您如何通过反向工程网站并查找其隐藏的API来避免浪费时间来首先创建网络抓取工具!
Learn web scraping in Nodejs & JavaScript by example projects with real websites! Craiglist, iMDB, AirBnB and more!
MP4 | Video: AVC 1280×720 | Audio: AAC 48KHz 2ch | Duration: 11h 1m | 7.8 GB | Language: English
What you’ll learn
Be able to scrape jobs from a page on Craigslist
Learn how to use Request
Learn how to use NightmareJS
Learn how to use Puppeteer
Learn how to scrape elements without any identifiable classes or id’s
Learn how to save scraping data to CSV
Learn how to save scraping data to MongoDb
Learn how to scrape Facebook using only Request!
Learn how you can reverse engineer sites and find hidden API’s!
Learn different technologies used for scraping, and when it’s best to use them
Learn how to scrape sites using authentication
Learn how to scrape HTML tables using Request/Cheerio
{kind=link}