这是一套基于机器学习的开源AI语音合成Python源码,可生成一个实时语音克隆工具,它通过深度学习,只需要说话者几秒钟的原始音频,就能模仿该说话者的声音进行说话了。
演示视频
下载地址
英文版:
https://github.com/CorentinJ/Real-Time-Voice-Cloning
中文版:
https://github.com/babysor/Realtime-Voice-Clone-Chinese
快速开始
1.安装要求
按照原始存储库测试您是否已准备好所有环境。**Python 3.7 或更高版本 ** 需要运行工具箱。
- 安装PyTorch。
如果出现
ERROR: Could not find a version that satisfies the requirement torch==1.9.0+cu102 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2 )此错误可能是由于python版本低,请尝试使用3.9,它会成功安装
- 安装ffmpeg。
- 运行
pip install -r requirements.txt以安装剩余的必要软件包。 - 安装 webrtcvad
pip install webrtcvad-wheels(如果需要)
请注意,我们使用的是预训练的编码器/声码器而不是合成器,因为原始模型与中文符号不兼容。这意味着 demo_cli 目前不工作。
2. 用你的数据集训练合成器
- 下载 adatatang_200zh 或其他数据集并解压:确保您可以访问train文件夹中的所有 .wav
- 使用音频和 mel 频谱图进行预处理:
python pre.py <datasets_root>允许参数--dataset {dataset}支持 adatatang_200zh、magicdata、aishell3
如果出现这种情况
the page file is too small to complete the operation,请参考这个视频,将虚拟内存改为100G(102400),例如:当文件放在D盘时,D盘的虚拟内存就改变了。
- 训练合成器:
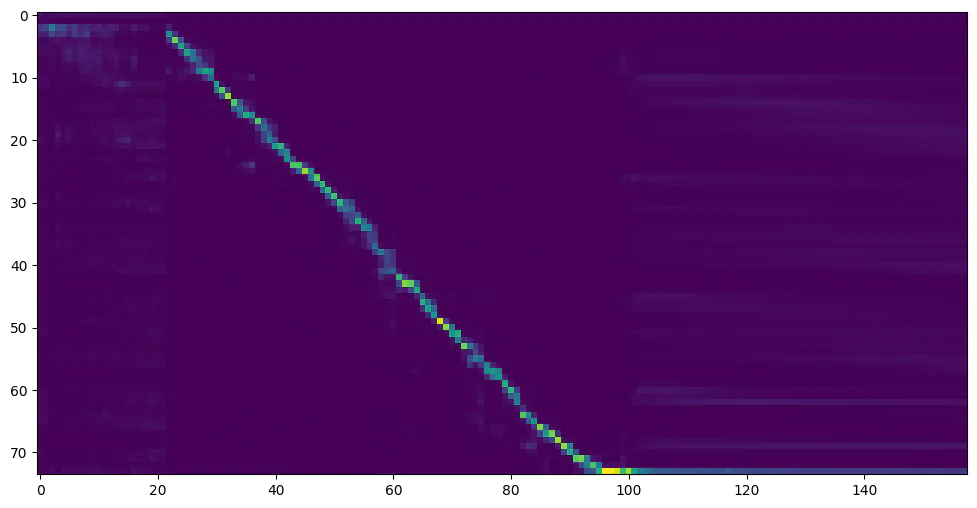
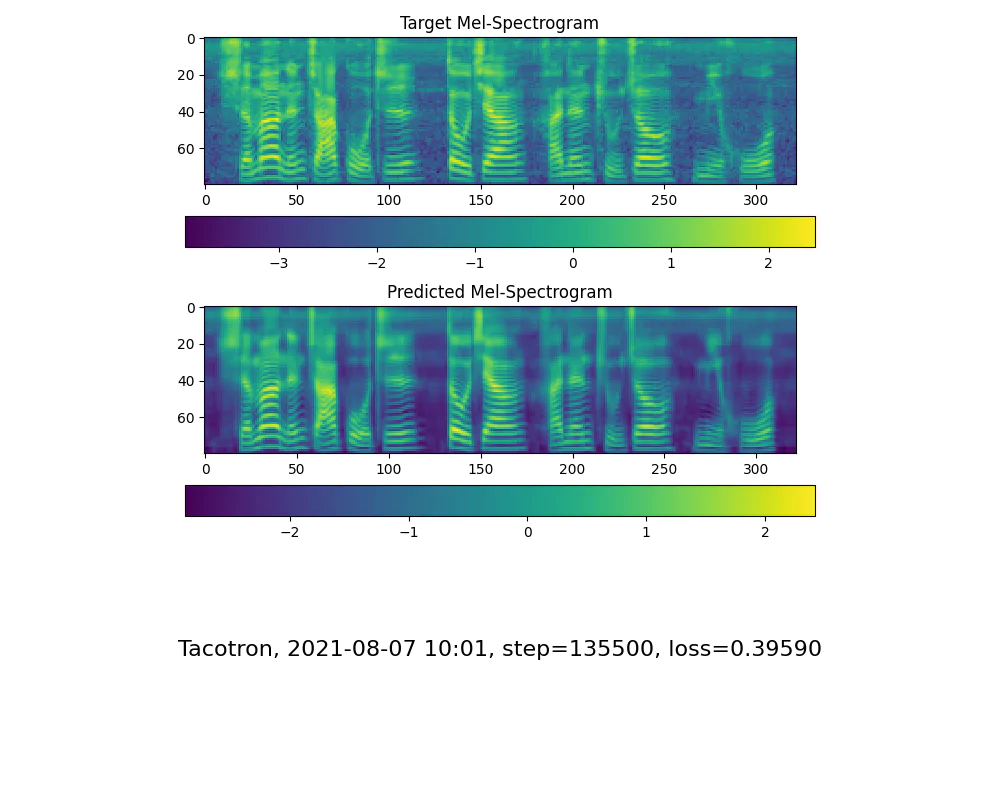
python synthesizer_train.py mandarin <datasets_root>/SV2TTS/synthesizer - 当您在训练文件夹synthesizer/saved_models/ 中看到 attention line show 和 loss 满足您的需要时,请转到下一步。
仅供参考,我的注意力是在 18k 步之后出现的,并且在 50k 步之后损失变得低于 0.4。
2.2 使用合成器的预训练模型
感谢社区,将分享一些模型:
| 作者 | 下载链接 | 上一个视频 |
|---|---|---|
| @miven | https://pan.baidu.com/s/1PI-hM3sn5wbeChRryX-RCQ代码:2021 | https://www.bilibili.com/video/BV1uh411B7AD/ |
我的早期训练模型的链接:百度云 代码:aid4
2.3 训练声码器(可选)
- 预处理数据:
python vocoder_preprocess.py <datasets_root> - 训练声码器:
python vocoder_train.py mandarin <datasets_root>
3. 启动工具箱
然后您可以尝试使用工具箱:
python demo_toolbox.py -d <datasets_root> 或者 python demo_toolbox.py
好消息?: 支持汉字
{kind=link}